

Monitoring & Observability (SLOs, KPIs, Alerts): Troubleshooting-Playbook (Symptome → Ursachen → Fix)
Geschätzte Lesezeit: ca. 8–10 Minuten
Key Takeaways
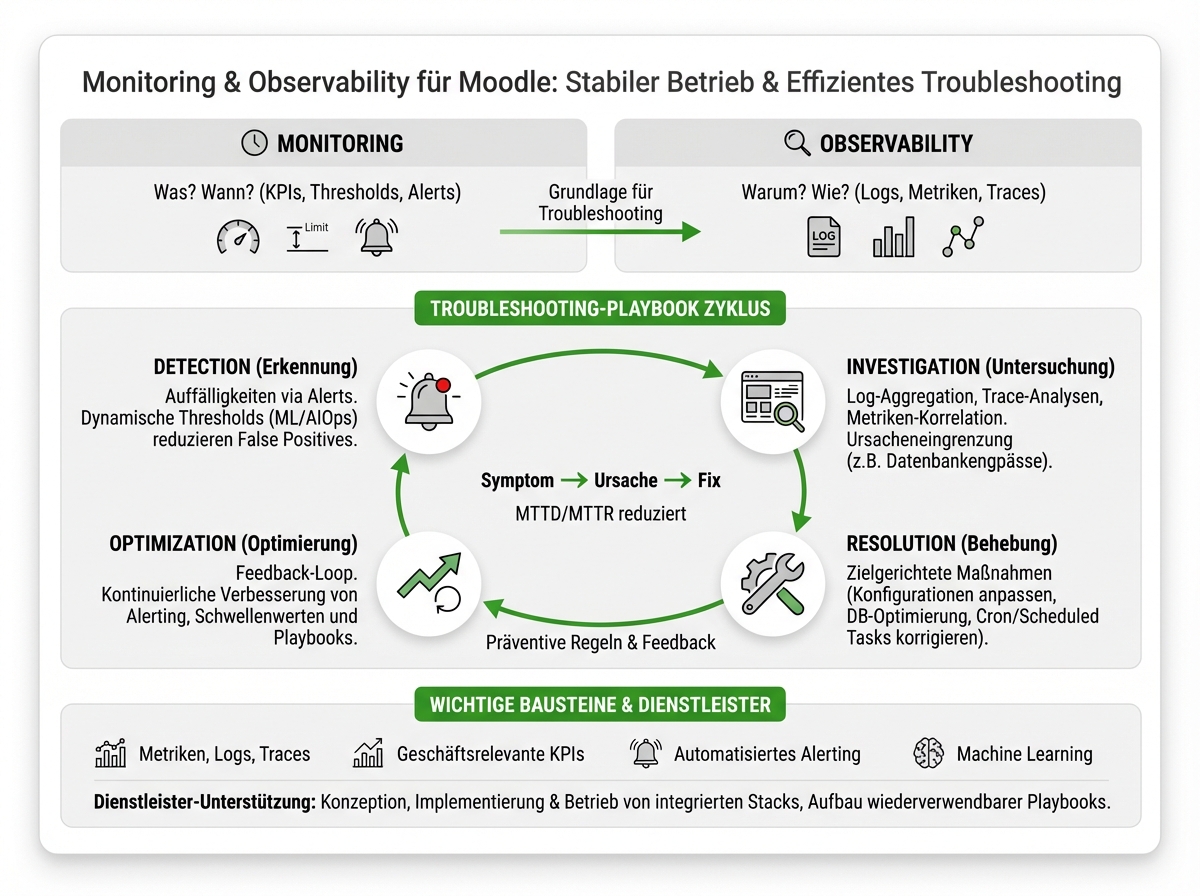
- Monitoring erkennt primär Symptome (Wann/Was) via KPIs & Thresholds, während Observability das Warum (Ursachen) über Logs, Metriken und Traces aufdeckt.
- Ein wiederholbares Playbook folgt dem Zyklus Symptom → Ursache → Fix und reduziert MTTD/MTTR durch klare Phasen (Detection, Investigation, Resolution, Optimization).
- Starre Schwellenwerte erzeugen häufig False Positives; moderne Ansätze nutzen Machine Learning/AIOps für dynamische Thresholds und Mustererkennung.
- Für Moodle sind zentrale Log-Aggregation, Trace-Analyse und Metriken-Korrelation entscheidend, um Engpässe (z.B. DB, Cron/Tasks, Backups) schnell einzugrenzen.
- Ein konsequenter Feedback-Loop verbessert Alerts kontinuierlich und macht Troubleshooting transparent, teamfähig und nachhaltig.
Inhaltsverzeichnis
- Warum ein strukturiertes Troubleshooting-Playbook für Moodle-Systeme unverzichtbar ist
- Der Unterschied: Monitoring erkennt Symptome, Observability deckt Ursachen auf
- Das Troubleshooting-Playbook: Systematische Fehlerbehebung von Symptom zu Fix
- Kernkomponenten für effizientes Troubleshooting in Moodle
- Mehrwert der Synergie: Monitoring & Observability im Zusammenspiel
- Handlungsanleitung: Best Practices für Moodle-Admins & Entscheider
- Quellen
- FAQ
Monitoring & Observability (SLOs, KPIs, Alerts): Warum ein strukturiertes Troubleshooting-Playbook für Moodle-Systeme unverzichtbar ist
Die stetige Verfügbarkeit und Performance von Moodle-Systemen ist für Bildungseinrichtungen und Unternehmen längst zum kritischen Erfolgsfaktor geworden. Fehlfunktionen, Ausfälle oder unerklärliche Performance-Einbußen bremsen jedoch nicht nur Lernende und Dozierende, sondern beeinträchtigen auch die Reputation und Zielerreichung Ihrer Organisation.
Hier helfen Monitoring und Observability, indem sie die Grundlage für ein effizientes Troubleshooting schaffen — von der Erkennung eines Symptoms, über die Ursachenanalyse bis zur zielgenauen Behebung. Ein strukturiertes Playbook macht dieses Vorgehen für DevOps und Moodle-Admins wiederholbar, transparent und nachhaltig.
In diesem Beitrag zeigen wir, wie Sie mit modernen Monitoring- und Observability-Praktiken Ihre Betriebs- und Fehlerbehebungsprozesse für Moodle revolutionieren können. Dabei gehen wir auf die Unterschiede und Synergieeffekte beider Ansätze ein, präsentieren praxiserprobte Best Practices und bieten konkrete Handlungsempfehlungen für Ihren Betrieb.
Der Unterschied: Monitoring erkennt Symptome, Observability deckt Ursachen auf
Monitoring und Observability werden häufig synonym verwendet, unterscheiden sich aber maßgeblich in ihrem Ansatz und ihrem Beitrag zur Fehlerbehebung.
Monitoring konzentriert sich auf das „Wann“ und „Was“. Es überwacht definierte Systemparameter (wie CPU-Last, Antwortzeiten, Ressourcenverbrauch) und schlägt Alarm, wenn vordefinierte Schwellenwerte (Thresholds) überschritten werden. Typische Fragen: „Ist die CPU-Auslastung hoch?“ oder „Gab es ungewöhnliche Verzögerungen beim Seitenaufbau?“. So erkennen Sie bekannte Fehlerzustände frühzeitig.
Observability hingegen adressiert das „Warum“ und „Wie“. Sie ermöglicht die tiefgreifende Analyse auch unerwarteter oder komplexer Probleme mittels Korrelation unterschiedlicher Datenquellen wie Logs, Metriken und Traces. Ziel der Observability ist, aus allen verfügbaren Informationen Beziehungen und Wechselwirkungen zu erkennen, um die eigentliche Ursache eines Problems zu identifizieren, statt sich auf das bloße Symptom zu konzentrieren.
Das Troubleshooting-Playbook: Systematische Fehlerbehebung von Symptom zu Fix
Ein durchdachter Incident-Response-Workflow folgt dem Zyklus Symptom → Ursache → Fix. Daraus ergibt sich ein wiederholbarer, lernender Prozess, der auch Ihr Moodle-Operations stabilisiert und beschleunigt.
1. Detection Phase: Symptome erkennen und einordnen
Ihre Fehlerbehebung beginnt mit Monitoring-Alerts. Die meisten Monitoring-Umgebungen arbeiten auf Basis fester Schwellenwerte und KPIs, die Abweichungen oder Anomalien im Betriebsverhalten Ihrer Moodle-Plattform melden.
Achtung: Starre, manuell definierte Schwellenwerte haben eine Tendenz zu False Positives oder sie erkennen subtile Probleme gar nicht erst. Moderne Monitoring-Systeme setzen daher zunehmend auf Machine Learning und AIOps, um dynamische Schwellenwerte und Mustererkennung einzuführen (Quelle).
Praxis-Tipp: Definieren Sie Ihre KPIs immer anhand Ihrer betrieblichen und didaktischen Ziele. Was ist für den Lernerfolg entscheidend? Welche Werte sind technisch wie didaktisch „kritisch“? So führen Alerts zu zielgerichteten Aktionen.
2. Investigation Phase: Ursachenanalyse durch Observability
Nachdem ein Monitoring-Alert ausgelöst wurde, beginnt die eigentliche Arbeit der Ursachenanalyse. Jetzt leisten Observability-Tools wertvolle Dienste:
- Log-Aggregation: Überwachen Sie alle System- und Anwendungslogs zentral. So lassen sich Ereignisse und Muster systemübergreifend korrelieren und abweichende Sequenzen identifizieren.
- Trace-Analyse: Analysieren Sie Abhängigkeiten und Interaktionen zwischen einzelnen Moodle-Services und Infrastrukturkomponenten. Traces machen sichtbar, an welcher Stelle in einer Prozesskette beispielsweise Netzwerklatenzen oder Datenbank-Engpässe entstehen.
- Metriken-Korrelation: Stellen Sie Zusammenhänge zwischen verschiedenen Kennzahlen (Last, Speicher, Benutzeranmeldungen etc.) her, um die Ursache komplexer Fehlerbilder zu ermitteln.
Beispiel: Das Monitoring meldet hohe Antwortzeiten. Die anschließend detaillierte Trace-Analyse zeigt, dass alle betroffenen Requests einen Umweg über einen überlasteten Datenbank-Server machen. Die Ursache liegt in einer unerwarteten Lastspitze durch automatisierte CLI-Backups (Quelle, Moodle-Dokumentation).
Das Herzstück bildet dabei der flexible, wiederholbare Analyse-Loop: Daten erfassen, Korrelationen analysieren, Hypothesen prüfen, Lösungen ableiten. Besonders hilfreich sind für Moodle-Betriebs- und Entwicklerteams Tools, die explorative, freie Recherchen ermöglichen und nicht nur auf vorgefertigten Dashboards basieren.
3. Resolution Phase: Zielgerichtete Behebung & nachhaltige Fehlervermeidung
Sobald Sie die eigentliche Ursache gefunden haben, können Sie gezielte Maßnahmen einleiten ― sei es ein Konfigurationsfix, die Optimierung einer Datenbankabfrage oder die Anpassung von Moodle-Scheduled Tasks (Moodle Scheduled Tasks, Moodle Cron, Moodle Task API).
Vorteil: Erkennt die Observability wiederkehrende Muster, wie einen deutlichen Log-Eintrag, der stets einem Memory-Leak vorausgeht, lässt sich ein präventives Monitoring-Alert generieren und im besten Fall die Störung schon verhindern oder mildern.
4. Optimization Phase: Feedback-Loop zur stetigen Verfeinerung
Nutzen Sie das erworbene Wissen, um Monitoring und Alerting laufend anzupassen. Jede erfolgreich analysierte Störung liefert wertvolle Hinweise zur Verbesserung Ihrer Schwellenwerte und Alert-Logik. So entwickelt sich Ihr Troubleshooting-Playbook kontinuierlich weiter und bleibt auf Höhe der Zeit.
Praxisbeispiel: Nach der Überführung eines Memory-Leaks, zu dem stets ein bestimmter, wiederkehrender Logpattern gehört, implementieren Sie einen neuen Alert exakt auf diesen Pattern und reduzieren so Ihre Mean Time to Detect (MTTD) erheblich.
Kernkomponenten für effizientes Troubleshooting in Moodle
| Komponente | Zweck | Praktische Anwendung im Moodle-Betrieb |
|---|---|---|
| Metriken | Zeitreihendaten zu Performance & Auslastung | Überwachen von CPU, RAM, Antwortzeiten, Benutzerzahl, Task-Laufzeiten |
| Logs | Detaillierte Ereignisdaten | Fehlersequenzen aufdecken, Ursache-Wirkungsketten erkennen |
| Traces | Überblick über Service-Flows & Abhängigkeiten | Identifizieren von Bottlenecks zwischen Moodle-Core, Datenbank und Plugins |
| KPIs | Business-relevante Zielwerte | Anomalien mit Auswirkungen direkt auf Lernprozesse priorisieren |
| Automatisiertes Alerting | Sofortige Benachrichtigung | Handlungsbereite, kontextbezogene Alarme an die richtigen Stellen schicken |
| Machine Learning | Dynamische Mustererkennung | Frühzeitige Warnung bei ungewöhnlichen, neuen Fehlerbildern |
Mehrwert der Synergie: Monitoring & Observability im Zusammenspiel
Setzen Sie auf den kombinierten Einsatz aus Monitoring und Observability, profitieren Sie in mehrfacher Hinsicht:
- Schnellere Fehlerbehebung: Automatisierte Alerts melden den Vorfall, Observability-Analysen führen blitzschnell zur Ursache.
- Höhere Ausfallsicherheit: Beobachtete Muster fließen als Lessons Learned sofort in neue Überwachungsregeln ein.
- Niedrigere MTTR (Mean Time To Resolution): Integrierte Dashboards mit korrelierten Datenpunkten ermöglichen eine effiziente Zusammenarbeit der beteiligten Teams.
- Gezieltere Optimierungen: Statt vagen Symptomen („Moodle ist langsam“) erkennen Sie präzise Ursachen („Response-Zeit langsamer für Kurs X, ausschließlich für Nutzergruppe Y nach Task Z“).
- Wertvoller Wissenstransfer: Jede Fehleranalyse zahlt auf das interne Know-how ein und schärft das kollektive Troubleshooting-Playbook.
Handlungsanleitung: Best Practices für Moodle-Admins & Entscheider
Eine systematische, kontinuierlich verbesserte Betriebsüberwachung bedeutet für Moodle-Admins und Entscheider zugleich Herausforderung und Chance. Die folgenden Empfehlungen helfen bei der erfolgreichen Umsetzung:
- Sammeln Sie alle Daten zentral: Logfiles, Metriken und Traces werden idealerweise automatisiert auf einer Plattform gebündelt, um Korrelationen zu ermöglichen.
- Nutzen Sie individuell zugeschnittene Dashboards: Sorgen Sie für übersichtliche, rollenbasierte Ansichten für verschiedene Stakeholder.
- Setzen Sie auf automatisierte und präzise Alerts: Alerts müssen unmittelbar handlungsleitend, konkret und nicht zu häufig sein.
- Integrieren Sie Whitebox- und strukturierte Logs in Ihre Systeme: Bereits beim Entwickeln und Installieren von Plugins und Schnittstellen sollten observierbare Parameter eingebaut werden.
- Installieren Sie Feedback-Schleifen: Überprüfen Sie regelmäßig die Effektivität der Alerts und Monitoring-Logik auf Basis Ihrer Incidents.
- Ermöglichen Sie explorative Analysen: Moderne Observability-Lösungen ermöglichen flexible, freie Rechercheoptionen für tiefgreifende Ursachenforschung.
- Gestalten Sie Ihre Fehlerbehebungs-Workflows reproduzierbar: Dokumentieren Sie neue Lessons Learned konsequent und übersichtlich in Ihrem eigenen Troubleshooting-Playbook und stellen Sie den Wissenstransfer im Team sicher.
Quellen
- Monitoring vs Observability: What’s the Difference? – logicmonitor.com
- Monitoring vs. Observability – AWS
- What is Observability: Key Components and Best Practices – honeycomb.io
- Network Observability: Capabilities, Challenges and Best Practices – selector.ai
- Observability vs Monitoring – dash0.com
- Moodle Docs: Site backup
- Moodle Docs: Cron
- Moodle Docs: Scheduled tasks
- Moodle Dev: Task API
- SRE Book – Effective Troubleshooting
FAQ
Warum reichen starre Schwellenwerte (Thresholds) im Moodle-Betrieb oft nicht aus?
Starre Thresholds erzeugen leicht False Positives (Alarmmüdigkeit) oder übersehen schleichende bzw. kontextabhängige Probleme. Moderne Monitoring-Ansätze nutzen deshalb zunehmend Machine Learning/AIOps für dynamische Schwellenwerte und Mustererkennung (u.a. Quelle).
Wie sieht ein strukturiertes Troubleshooting-Playbook konkret aus?
Ein praxistaugliches Playbook folgt einem wiederholbaren Zyklus: Detection (Symptome/Alerts) → Investigation (Observability: Logs/Metriken/Traces, Hypothesen) → Resolution (gezielter Fix, z.B. Konfiguration, DB, Tasks) → Optimization (Feedback-Loop, bessere Alerts/KPIs). Dieses Vorgehen senkt MTTD/MTTR und verbessert die Betriebsstabilität nachhaltig.
Welche Moodle-spezifischen Bereiche sind häufige Ursachen für Performance-Probleme?
Häufige Ursachen liegen in Abhängigkeiten wie Datenbank-Engpässen, Cron-/Task-Ausführungen oder Backups. Relevante Einstiegspunkte sind u.a. Moodle Cron, Scheduled tasks, Task API sowie Site backup. Observability hilft, diese Faktoren über Traces/Logs/Metriken sauber zu korrelieren.
Wie verbessert Observability das Alerting langfristig?
Wenn Observability wiederkehrende Muster identifiziert (z.B. ein Logpattern, das einem Memory-Leak vorausgeht), können daraus präventive Alerts abgeleitet werden. So werden Störungen früher erkannt oder sogar verhindert, und das Playbook wird durch den kontinuierlichen Feedback-Loop stetig präziser (u.a. Quelle).